Predictive Application
Web service aimed to let users utilize machine learning technology for their purposes. It includes visualization tools and special tools helping to create a Machine Learning Model with no deep data science knowledge is required.
The first step is to create a model. Once the model is created it helps with further predictions. There’s no need to create specific code for predictions and no need to control any infrastructure.
All these options are presented in the interface so it’s easy to understand and navigate through the platform. The variety of result visualization allows to choose the best training methods and get the best prediction result.
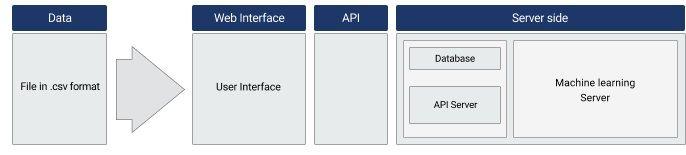
Scheme of the system architecture:


Sampling option


In order to make a reliable estimation of the performance for the selected machine learning model user can select between several cross-validation and sampling techniques.
-
Sequential sampling splits data set exactly in 2 parts. You can select proportion of the dataset which will be used for training. The remaining data will be used to test the performance of the model. Selection is done in sequential order meaning that training part will be taken from the beginning of the file.
-
Random sampling splits data set exactly in 2 parts. You can select proportion of the dataset which will be used for training. The remaining data will be used to test the performance of the model. The difference with the sequential option is based on the fact that selection of the training portion (specific rows from the dataset) is done randomly meaning that you can get different training sets each time you apply this option.
-
K-fold cross-validation: Algorithm splits the file into k non-overlapping equally sized parts. Each part is used in turn as a validation set while the remaining of the data are used for training. Results of each validation step are aggregated together to form final performance metric.
-
Bootstrap cross-validation: The algorithm performs random sampling k times generating k training and k validation subsets. Each part is used in turn to perform training and validation of the trained model. Results produced at each validation step are aggregated together to form the final performance metric.
Random sampling: training data are selected randomly over a file.
K-fold cross-validation: file is split into k equally-sized subsets, each used for training in turn.
Bootstrap: k independent random samples for k training and validation subsets, each used in its turn.
The horizontal scale is a way to setup a proportion of the training set compared to the whole size of the dataset when applicable.

Horizontal scale - separating the file into two parts. Training set - a part of the dataset, which will be used for model training. Evaluation set - a part of the dataset, which will be used for evaluation.
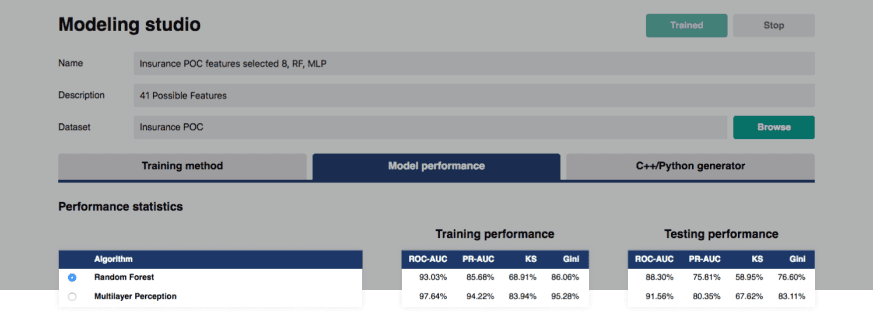
Modeling studio

Performance statistics provide detailed information on each algorithm selected for training based on the results obtained during the validation process. Various metrics allow estimating performance and select an optimal model fit to specific use cases or data.

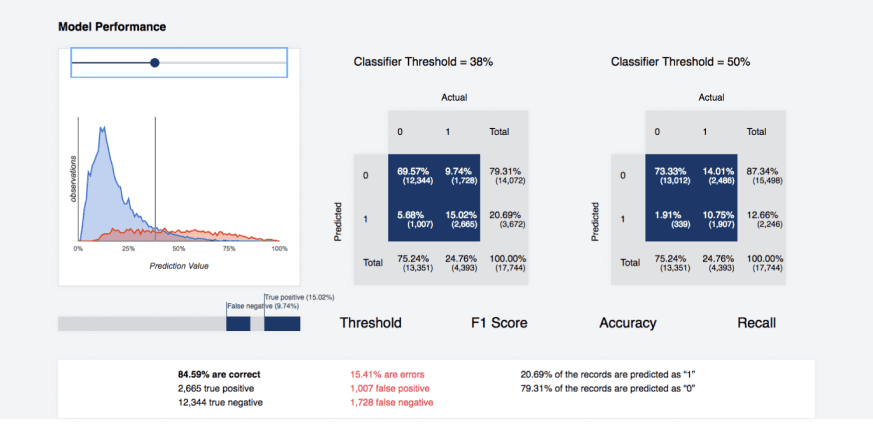
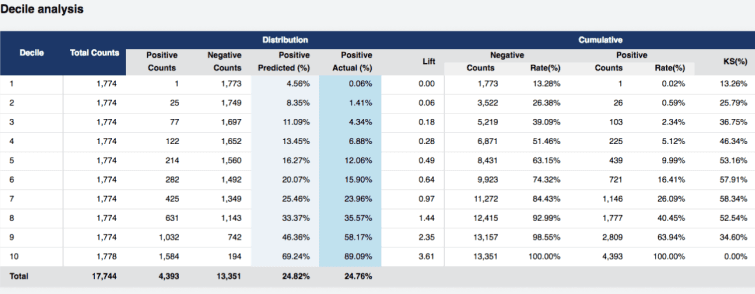
Statistical analysis of the probability distribution for the predicted class labels allows users to obtain a better understanding of the optimal confidence level required to make decisions about label assignment. Both textual and visual information is provided in order to make conclusions about the distribution of the correct prediction numbers for each threshold. Additionally to tabular representation the charts are provided to illustrate this distribution as well as some of the commonly used metrics for the same purpose (Kolmogorov-Smirnov, lift, Gini, etc). Additional it is possible to generate a confusion table for each threshold level.


Prediction studio

After the process of generation and training model tuning is completed and analysis of the performance shows acceptable results, user can save this model and use it for prediction on the new data file later.
In the interface, user can select a model, upload a file of the same structure that was used for training, apply a prediction model to the data and eventually review and download results.
Similar Projects
Multi-Channel AI Platform
A chatbot platform with NLP, built for flexible interactions, cross-channel deployment, and continuous product expansion.
Automatic pancreas detection in 3d CT scans
Multi-stage system of pancreas segmentation using CT scans.
Custom Voice-Over Training Software
A scalable web solution for real-time dubbing and remote voice training.