Приложение для создания предсказательных моделей
Веб-сервис, позволяющий создавать AI-модели, не обладая при этом глубокими знаниями в области машинного обучения.
Первый шаг - это создание модели. Как только модель создана, она помогает пользователю в дальнейших прогнозах. Нет необходимости писать специальный код для предсказаний и нет необходимости подготавливать какую-либо инфраструктуру.
Разнообразие визуализации результатов позволяет выбрать наилучшие методы обучения и получить наилучший результат прогнозирования.


Варианты семплинга


Чтобы произвести надежную оценку производительности выбранной модели машинного обучения, пользователь может выбрать один из нескольких методов перекрестной проверки и семплинга.
-
Последовательная выборка разбивает набор данных точно на 2 части. Вы можете выбрать долю набора данных, которая будет использоваться для обучения. Остальные данные будут использованы для тестирования производительности модели. Выбор производится в последовательном порядке, что означает, что обучающая часть будет взята с начала файла.
-
Случайная выборка тоже разбивает набор данных на 2 части. Вы можете выбрать долю набора данных, которая будет использоваться для обучения. Остальные данные будут использованы для тестирования производительности модели. Разница с последовательным вариантом основана на том факте, что выбор обучающей части (определенных строк из набора данных) выполняется случайным образом, что означает, что вы можете получать разные обучающие наборы каждый раз, когда применяете этот параметр.
-
K-кратная перекрестная проверка: алгоритм разбивает файл на k непересекающихся частей одинакового размера. Каждая часть используется по очереди в качестве проверочного набора, в то время как остальные данные используются для обучения. Результаты каждого этапа проверки суммируются вместе, чтобы сформировать окончательный показатель производительности.
-
Перекрестная проверка начальной загрузки: алгоритм выполняет случайную выборку k раз, генерируя k обучающих и k проверочных подмножеств. Каждая часть используется по очереди для выполнения обучения и валидации обученной модели. Результаты, полученные на каждом этапе проверки, суммируются вместе, чтобы сформировать окончательный показатель производительности.
Случайная выборка: обучающие данные выбираются случайным образом из файла.
K-кратная перекрестная проверка: файл разбивается на k подмножеств одинакового размера, каждое из которых по очереди используется для обучения.
Перекрестная проверка начальной загрузки: k независимых случайных выборок для k обучающих и валидационных подмножеств, каждое из которых используется в свою очередь.
Горизонтальный масштаб - это способ настроить пропорцию обучающего набора по сравнению со всем размером набора данных, когда это применимо.

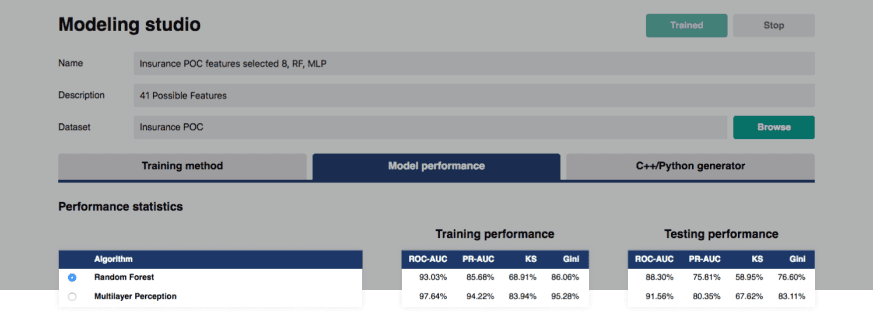
Студия моделирования

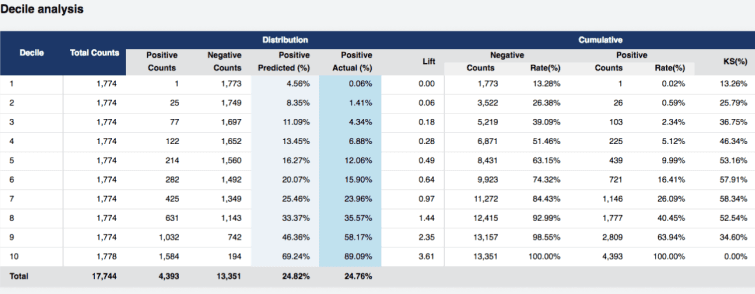
Статистика производительности предоставляет подробную информацию по каждому алгоритму, выбранному для обучения, на основе результатов, полученных в процессе валидации. Различные показатели позволяют оценить производительность и выбрать оптимальную модель, соответствующую конкретным случаям использования или данным.

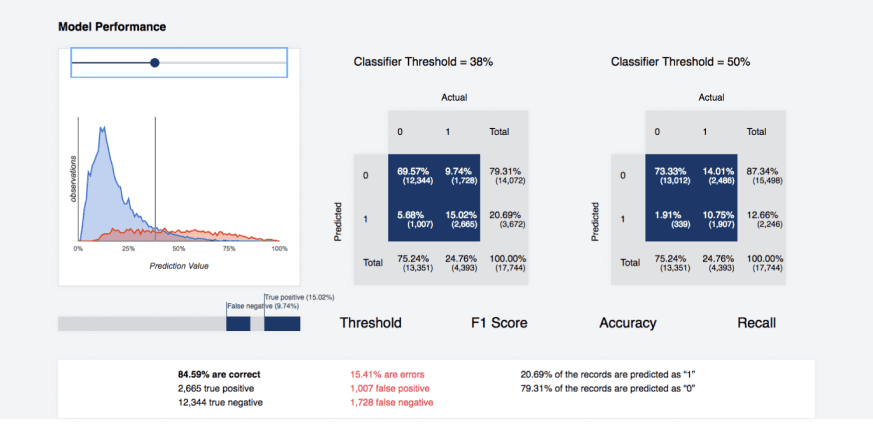
Статистический анализ распределения вероятностей для предсказанных меток классов позволяет пользователям получить лучшее представление об оптимальном уровне достоверности, необходимом для принятия решений о присвоении меток. Как текстовая, так и визуальная информация предоставляется для того, чтобы сделать выводы о распределении правильных чисел прогнозирования для каждого порога. В дополнение к табличному представлению представлены диаграммы, иллюстрирующие это распределение, а также некоторые из часто используемых показателей для той же цели (Колмогоров-Смирнов, лифт, Джини и т.д.). Дополнительно можно сгенерировать матрицу путаницы для каждого порогового уровня.


Студия предсказаний

После того, как процесс генерации и настройки обучающей модели завершен и анализ производительности показывает приемлемые результаты, пользователь может сохранить эту модель и использовать ее для прогнозирования позже.
В интерфейсе пользователь может выбрать модель, загрузить файл той же структуры, которая использовалась для обучения, применить модель прогнозирования к данным и в конечном итоге просмотреть и загрузить результаты.
Похожие проекты
Автоматизация кадрового агентства
Внедрили ИИ для рутинных задач: в 6 раз сократили время на подбор релевантных кандидатов.
Прогнозная модель для сервиса каршеринга
Обучили ML-модель предсказывать цены на аренду авто.
Интернет-магазин ювелирных украшений
Кастомное e-commerce решение для монобрендового онлайн-магазина.