Прогнозирование цен
для сервиса каршеринга




Клиент
Владелец службы краткосрочной аренды автомобилей в Японии. По сравнению с конкурентами компания среднего масштаба, но работает по всей стране и имеет свой сервис онлайн-бронирования.
Ключевой критерий для пользователей при выборе компании-арендатора – цена. Чтобы реагировать на изменение спроса и предложения в реальном времени, сервисы каршеринга применяют динамическое ценообразование.
Владелец понимал: чтобы его сервис всегда пользовался спросом, а машины не простаивали в автопарке, цена на аренду должна быть релевантной. Немного ниже, чем у конкурентов, но достаточной, чтобы покрыть целый ряд бизнес-расходов и приносить стабильную прибыль сверху.
Как найти этот тонкий баланс и верно рассчитать цену? Правильный ответ – поручить задачу искусственному интеллекту.
Вызовы
В 2020 году владелец обратился к нам. На тот момент он и сам не понимал, какую область Data Science лучше использовать под его бизнес-задачу.
Для нас выбор был очевиден. Большие объемы данных, выявление закономерностей, точный прогноз – работа для машинного обучения.
Какие метрики предсказывать?
С этим было сложнее. Базовая цена на аренду авто складывается из цели поездки, класса машины, сезонности, географии, сроков бронирования. Причем факторы коррелируют друг с другом.
Если учитывать их все, понадобится обработать очень много данных. Стоимость разработки такого алгоритма улетит в космос. Как решить?
Вариант #1
Привязать расчеты к конкретной машине и собирать статистику по геолокации в режиме реального времени. Машины и их количество постоянно меняются; в 2020 году в одном только Токио насчитывалось 62 муниципалитета. Как поддерживать актуальность данных и во сколько это обойдется клиенту?

Вариант #2
Базировать алгоритм на исторических данных. Они отражают естественные колебания рынка. Из них можно вывести более точный процент падения или роста спроса, затратив меньше времени.
Остановились на этом варианте и выбрали две модели: первая – история спроса и цен для разных типов автомобилей, вторая – история погоды в Японии.
Как обучали ML-модель:
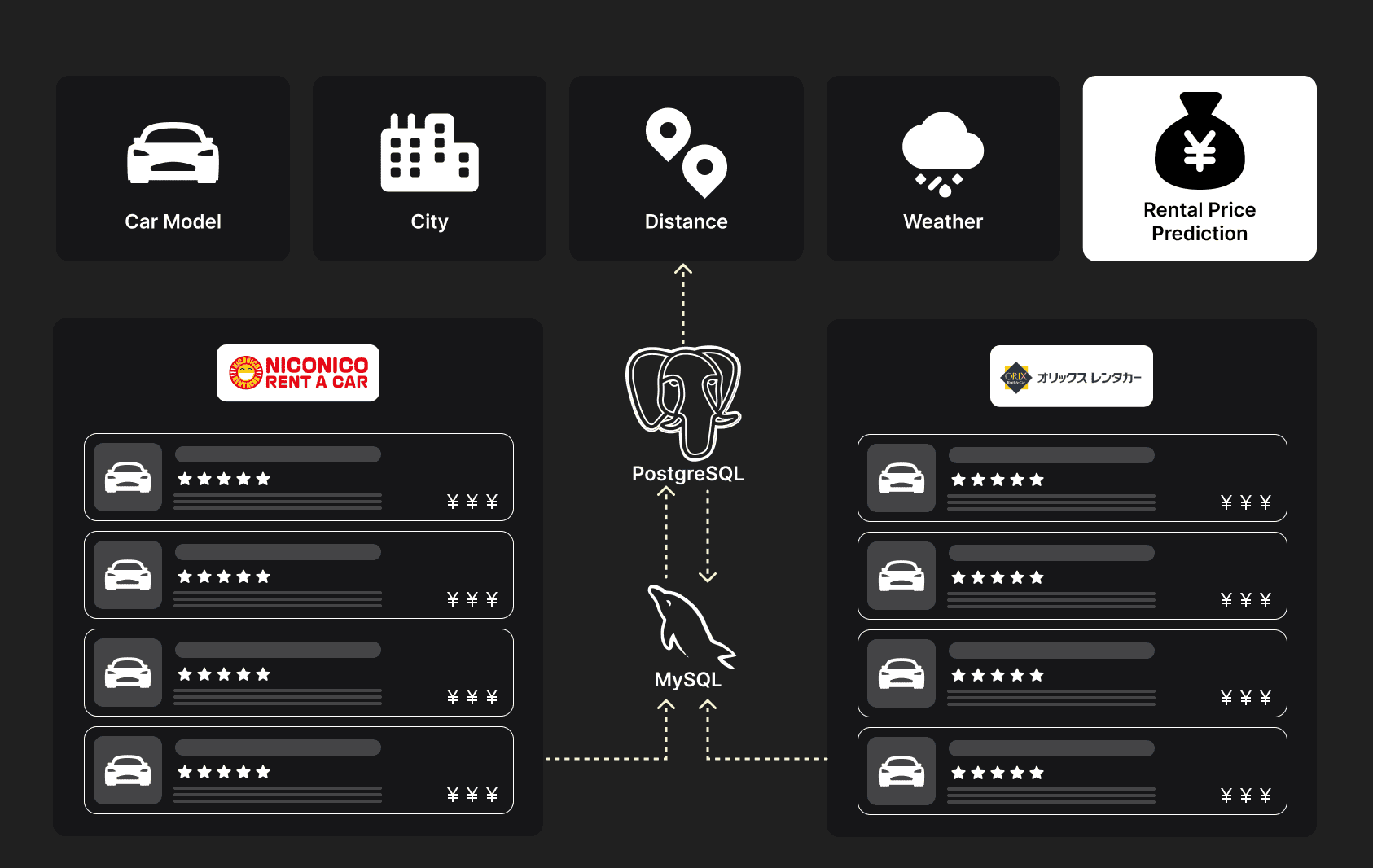
Шаг 1. Данные компании клиента
Сначала проанализировали, что происходило у клиента: когда и какая машина простаивала, когда ее брали в аренду, какая была базовая цена и итоговая стоимость. Обработали все в формате .csv и записали в таблицы MySQL. От них будем отталкиваться при формировании прогнозов.
Для записи данных добавили вспомогательные таблицы, чтобы сопоставить японские названия с теми, которые используются в MySQL.
Шаг 2. Исторические данные конкурентов
Владелец предложил ориентироваться на двух агрегаторов японского рынка: Orix и Niconico. Мы согласились: обе базы крупные, они покажут точное отражение рыночной ситуации плюс дадут переменные (сезонность, экономическая составляющая, характеристики разных типов машин).
– Сравнили исторические данные агрегаторов с данными о сервисах каршеринга в PostgreSQL: цены, расстояние и прогнозы других обученных моделей.
– Информацию брали только за последний год, потому что устаревшие данные исказят картину и сделают прогноз неточным.
– Скорректировали обнаруженные несоответствия между данными компании клиента, данными конкурентов и данными из PostgreSQL. Это и будет нашей обучающей выборкой для тренировки моделей.
Шаг 3. Обучение и тестирование алгоритма
– Очистили полученные данные от шумов (например, искажение из-за времени суток или праздничных дат), чтобы увеличить эффективность. Не убирали классы и типы машин, даже если таких марок у клиента пока не было: получился запас на случай, если клиент решит разнообразить автопарк.
– Для обучения использовали модель XGBoost, свойства подбирали методом перекрестной проверки:
• Для моделей «цена» и «спрос» – по компании, типу автомобиля, продолжительности брони, состоянию рынка на момент аренды.
• Для модели «погода» – по локации, погоде, сезонности. Если реальных данных о погоде на конкретную дату или место не было, использовали вспомогательные модели прогноза погоды. Они базируются на средних значениях за выбранный период.
– Для обучения взяли 80% данных, остальное оставили для тестов. Это помогло проверить качество предсказаний. Проанализировали результаты, сравнили с фактическими цифрами. Выявили причины отклонений в прогнозах и скорректировали модель, повысив ее точность.
Технологии

Бэкенд
Python

База данных
MySQL

База данных
PostgreSQL

Библиотека
XGBoost

Брокер сообщений
NATS
Результат
На работу ушло 11,5 месяцев. Клиент был терпелив, но его ожидание окупилось: пользователи довольны ценой и чаще бронируют автомобили. Мы смогли обеспечить высокую точность модели, потому что правильно подобрали метрики, объемы исходных данных, методы анализа и обучения ML-модели.
такой точности прогноза мы добились.
сократился простой автомобилей.

Что происходит дальше:
Мы получаем запрос, обрабатываем его в течение 24 часов и связываемся по указанным вами e‑mail или телефону для уточнения деталей.
Подключаем аналитиков и разработчиков. Совместно они составляют проектное предложение с указанием объемов работ, сроков, стоимости и размера команды.
Договариваемся с вами о следующей встрече, чтобы согласовать предложение.
Когда все детали улажены, мы подписываем договор и сразу же приступаем к работе.