Machine learning algorithms for credit scoring data classification
Backend for performance demonstration of various ML algorithms
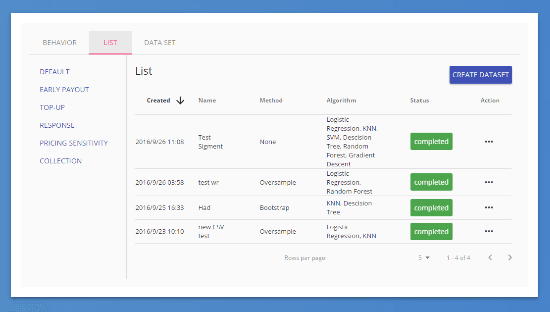
Our developers have designed and developed the R language-based classification system for defaulted/non-defaulted loans, the system is based on the following points:
- data loading and data encoding for categorical data types,
- data normalization and pre-processing,
- data sampling,
- data classification and cross-validation for robust performance estimation.
The system allows testing 3 variants of data sampling (oversampling, undersampling and bootstrap sampling) and 6 variants of classification algorithms (KNN, SVM, logistic regression, stochastic gradient descent, decision tree and random forest).
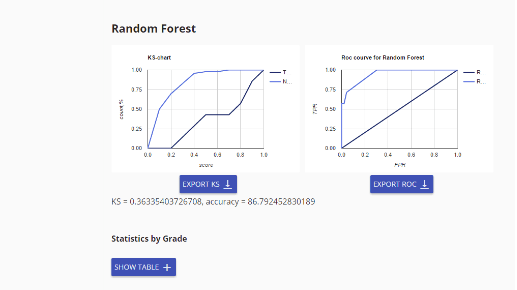
As a result of algorithms implementation, the user receives a detailed information about the classification performance using such metrics as MSE, Kolmogorov-Smirnov statistics, and ROC curves.
The system was deployed on AWS server and connected via API to the web interface. Both APIs and web interface were developed by our web developers as well.
The main concern of the system implementation on the server was in the data processing memory usage, that was successfully overpassed by code optimization for memory and computational resources usage.


Similar Projects
Virtual try-on tool for makeup products
The system consists of a face detection and segmentation model and an algorithm that allows recoloring objects without losing their original texture.
Online sign language interpreter
AI algorithm that converts video of a person using sign language into a text transcript
Online games
Online games store